
노도 구성 및 역할
RDB vs OpenSearch 용어 비교
관계형 데이터베이스 | OpenSearch | |
1 | 테이블(table) | 인덱스(index) |
2 | 한행(row) | 문서(document) |
3 | 컬럼(column) | 필드(field) |
4 | 물리파티션 | 샤드(shards) |
5 | 스키마 | 매핑(mapping) |
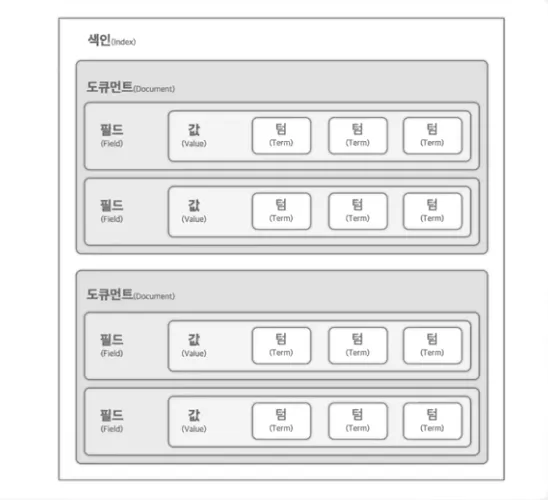
인덱스의 구성
•
인덱스: 데이터 저장 및 검색을 위한 주요 데이터 구조
•
도큐먼트: 인덱스 내에 JSON 형식의 데이터 기본 단위
•
필드와 값: 각 문서는 데이터 속성이나 특성을 나타내는 필드로 구성
•
텀: 필드 내 데이터의 단위로 OpenSearch에 색인되고 검색 할 단어 저장
노드의 개념
노드의 정의 | 클러스터를 구성하는 개별 서버 인스턴스 |
역할과 기능 | 데이터 저장, 검색, 분석 등 포함한 다양한 작업 처리 |
클라스터 연결 | 각 노드는 고유한 이름과 식별정보(IP, Port)를 가지고 클러스터 내에서 협력 |
노드의 유형 | 마스터 노드, 데이터 노드, 코디네이팅 노드 등 각각의 특정 역할을 수행 |
노드의 구성의 중요성 | 클러스터 성능과 안정성에 영향을 미침 |
마스터 노드
1.
클러스터의 핵심 관리자로 클러스터의 안정적인 운영을 책임지는 노드
2.
클러스터 내 인덱스 생성 및 삭제, 노드 관리, 샤드 분배 등 중요한 결정을 내림
3.
클러스터의 연속적인 서비스 제공을 위해 적어도 한개 이상의 마스터 노드가 필요
4.
운영환경에서는 3개 이상의 마스터 노드를 두어 장애 발생 시 안정성을 보장하는 것을 권장
a.
마스터 후보 노드를 하나만 놓게 된다면 마스터 노드가 유실되었을 때 클러스터 전체가 동작하지 않을 위험이 존재.
b.
만약 네트워크 단절이 생겨 마스터 후보 노드가 짝 수 일 경우 각자 분리되면서 다른 클러스터로 구성되어 동작하는 경우가 있을 수 있음(Split brain). 홀 수 마스터 후보 노드 구성을 추천 (참고 링크)
5.
클러스터 상태를 모니터링 하며, 필요한 경우 마스터 노드 역할을 수행 할 수 있는 노드로의 전환을 관리
6.
마스터 후보 노드는 데이터 노드가 될 수 있지만, 클러스터의 안정성과 성능을 고려했을때, 전용 마스터 후보 노드를 두는 것이 권장사항
# 마스터 후보 노드
node.master: false
node.data: false
# 데이터 노드이자 마스터 후보 노드
node.master: true
node.data: true
# 데이터 노드만
node.master: false
node.data: true
YAML
복사
데이터 노드
1.
클러스터에서 데이터를 실제로 저장하고 관리하는 역할
2.
색인, 검색, 집계 등을 담당하며, CPU, I/O, 메모리와 같은 하드웨어 리소스를 많이 소모
3.
클러스터 안정성을 위해, 데이터 노드는 적적할 수의 노드를 유지하고 장애 발생시를 대비해 적절한 샤드 운영을 해야 함
4.
데이터 노드의 종류는 어려가지가 있으며 데이터의 특성과 접근 패턴에 맞게 조정
5.
데이터 노드 구성은 성능 최적화와 클러스터 안정성, 비용 적인 측면에서 직접적인 영향을 끼침(컴퓨팅 파워 비용 등)
데이터 노드 종류
1.
data_content
a.
지속적으로 유지되어야 하는 데이터를 저장, 주로 읽기 작업이 많은 검색 및 집계 쿼리에 사용
2.
data_hot
a.
최신 시계열 데이터를 바르게 읽고 쓰는데 필요하며, 고성능 SSD 같은 저장 장치를 사용하여 최근 데이터 엑세스
3.
data_warm
a.
쿼리 빈도가 낮은 데이터를 보관하며, 비용 효율적인 HDD를 사용하여, 몇주 전 데이터를 저장
4.
data_cold
a.
빠르게 검색할 필요가 없는 오래된 데이터를 보관하며, 필요에 따라 데이터를 이동시켜 저장 공간을 효율적으로 사용
5.
data_frozen
a.
거의 사용되지 않거나 아카이브 목적의 데이터를 저장하며, 데이터 보존이 주된 목적일 때 사용(S3 등 보관)
그 밖의 노드 종류
1.
코디네이팅 노드
a.
클러스터의 요청을 라우팅하고 상태를 관리하는 역할로 대규모 클러스터에서는 별도로 분리하여 운영
2.
머신러닝 노드
a.
머신러닝 기능을 제공하며, 데이터학습, 이상탐지, 예측 등 작업을 처리
3.
리모드 클러스터 클라이언트
a.
다른 클러스터와 연결을 관리하고 여러 클러스터 간의 데이터 검색이 가능하게 담당
4.
트랜스폼 노드
a.
인덱스 간 데이터를 자동으로 복사하거나 변환하는 역할을 수행
모든 설정과 역할은?
•
opensearch.yml 을 통해 가능
클러스터에 대한 이해
1.
하나 이상의 노드로 구성하여 노드들이 협력하여 데이터 저장, 검색 및 분석 작업을 수행
2.
각 노드는 고유한 이름, IP를 통해 식별하며 클러스터에 가입하여 클러스터 전반적인 상태를 관리, 데이터 관련 작업을 처리
3.
다양한 룰을 통해 각 노드에 특정 기능과 권한을 할당
4.
데이터의 안정성과 지속적인 가용석을 보장하기 위해 가용영역에 걸쳐 노드를 분산 배치
5.
대용량 데이터를 효율적으로 처리 할 수 있으며, 필요에 따라 확장이 용이
노드 종류별 요구되는 시스템 리소스
저장소 | 메모리 | CPU | |
데이터 노드 | Extreme | High | High |
마스터 노드 | Low | Low | Low |
인제스트 노드 | Low | Medium | High |
코디네이팅 노드 | Low | Medium | Medium |
1.
데이터 노드
a.
색인, 검색, 집계 등 다양한 작업을 하기 때문에 많은 리소스가 필요함
b.
보통은 16G 이상의 메모리가 권장
2.
마스터 노드
a.
주로 클러스터의 상태 관리와 같은 경량작업을 위주로 하기 때문
b.
보통 2G 이상의 메모리가 권장
3.
인제스트 노드
a.
데이터 전처리 과정, 인덱싱 파이프 라인 작업등을 처리해야하므로 중간정도의 리소스가 필요함
b.
보통 8G 이상의 메모리 권장
4.
코디네이팅 노드
a.
주로 검색 요청 처리를 하기 위한 노드
b.
보통 작은 규모의 클러스터에서는 2G 메모리 권장